Batching vs Incremental Runs, Idempotency, and Schema Versioning
A conversational guide to building reliable data and agentic pipelines that don’t fall apart in production.
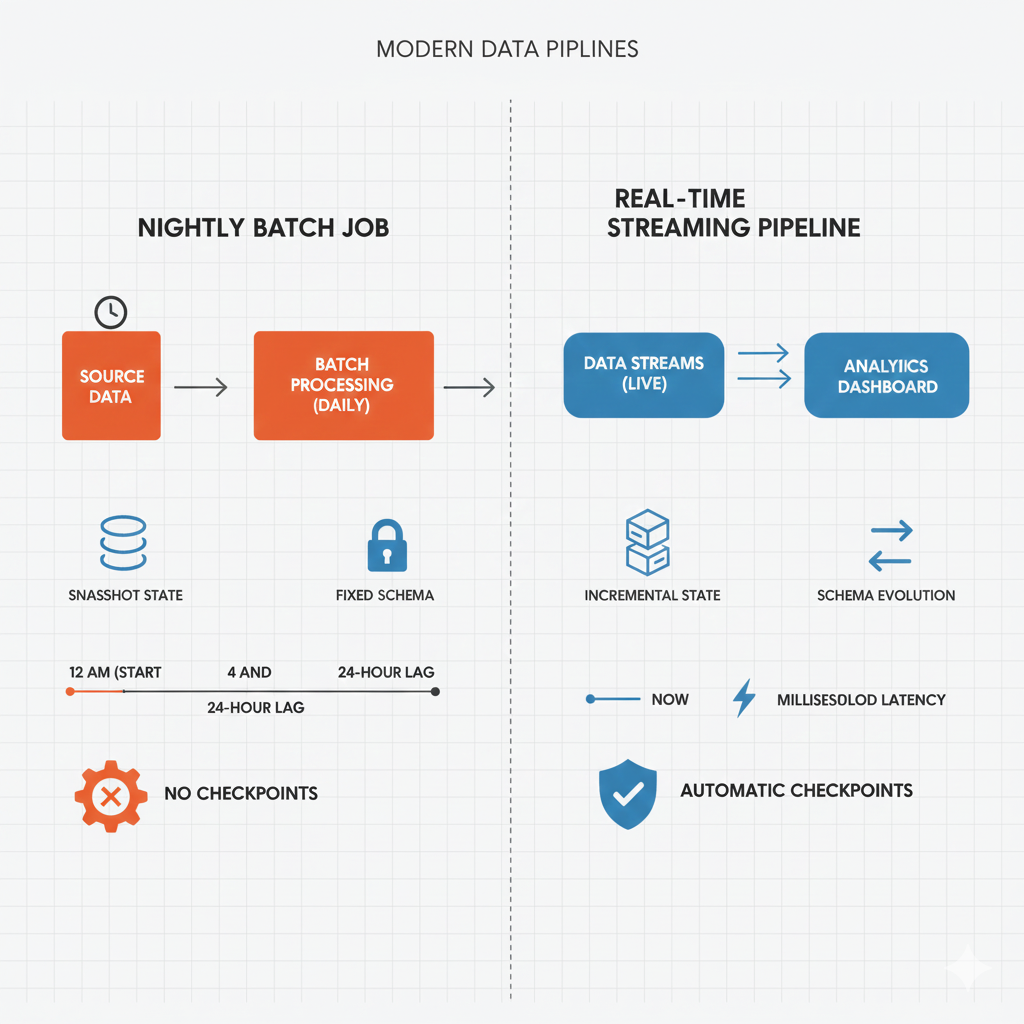
If you’re building modern data, ML, or agentic systems, you eventually run into three design questions:
- How often should this run? (batching vs incremental)
- What happens if it runs twice? (idempotency)
- What if the data shape changes? (schema & versioning)
You can ignore these for a prototype. But the minute your pipeline matters to real customers—or feeds LLM agents that make decisions—you need crisp answers. Let’s walk through each piece in plain language.
Batching: Big, Predictable Chunks
Batching means you process a whole chunk of data at once, usually on a cadence: nightly, hourly, every Monday at 2am. Think “rebuild yesterday’s metrics” or “re-embed every document in the Bronze layer.”
The upside is simplicity. You know exactly what the input slice is, you can tag the output with “2025‑11‑20 batch,” and if something goes wrong you just rerun that batch. Data lineage and provenance are very clean: this table came from that run.
The tradeoff is latency and cost. Full reruns over growing datasets get slow and expensive. And if you’re feeding those results into an agent, yesterday’s batch may already feel stale to a user who just changed a record five minutes ago.
Incremental Runs: Only What Changed
Incremental runs try to solve that by processing only “what changed since the last good run.” You rely on things like CDC streams, watermarks, or a last_updated_at column to decide what’s new.
This is fantastic for responsiveness: dashboards feel fresh, search indexes stay up to date, and agent memory stays in sync with reality. It’s also usually cheaper, because you’re not re-touching ancient rows that haven’t changed in years.
The catch is correctness. Now you’re carrying state: “What was the last offset I processed? Did I double-count that event? What if the job failed halfway through?” Lineage gets more subtle too—the current table is the sum of many tiny updates, not one neat snapshot.
Idempotency: Safe to Hit the Big Red Button Twice
This is where idempotency saves you. An idempotent step can run once, twice, or ten times and you still end up in the same correct state.
Concretely, that usually means:
- Using deterministic transforms (same input → same output).
- Writing with upserts/merges keyed on natural business IDs, not auto‑incrementing IDs.
- Avoiding blind “append only” side effects where each retry creates duplicates.
In data + agent systems, idempotency is what lets you safely retry a stuck job, replay a subset of events, or re-run an “enrich with embeddings” step without creating conflicting versions of the same fact in your vector store.
Schema and Versioning: Data Shapes Over Time
Even if your scheduling and idempotency are rock solid, your schema will change. New columns, new JSON fields, new event types. If you don’t treat schema evolution as a first‑class concern, you’ll end up with silent breakage and brittle agents.
Good schema/versioning discipline might include:
- Table versioning with formats like Delta/Iceberg so you can time‑travel and roll back.
- Data contracts between producers and consumers, with semantic versions for breaking changes.
- Migration workflows when you must rename a field or change its meaning, rather than “just deploy it.”
When an LLM agent answers “Why did revenue drop?”, you want to be able to say: this came from table version X, schema version Y, as of commit Z in the transformation repo. That’s provenance, not vibes.
How It All Fits Together in Agentic Pipelines
Put it together and you get a simple mental model:
- Batch vs incremental decides when data moves.
- Idempotency decides how safely it moves and whether retries are boring instead of scary.
- Schema/versioning decides what the data means as your system and organization evolve.
For classic analytics, that means trustworthy dashboards and backfills. For ML, it means reproducible training sets and auditability. For agentic systems, it means your retrieval, reasoning, and “memory” layers behave like infrastructure, not a science experiment.
You don’t need a perfect solution to all three before you ship. But having a conscious answer—which parts are batch vs incremental, which steps are idempotent, and how schemas evolve—is the line between a clever demo and a pipeline you’re comfortable betting your business on.